Token Bucket Rate Limiting with Interval and Greedy Refillers
A hands-on look at the Token Bucket algorithm, how it handles bursty traffic, why refill strategy matters, and how to build it in Java.
Part of the Rate Limiting series
Table of Contents
The Token Bucket Rate Limiting algorithm implements rate limiting by maintaining a fixed-capacity bucket that holds tokens. Tokens are added at a consistent rate, and their count never exceeds the bucket’s capacity. To process a request, the algorithm checks for sufficient tokens in the bucket, deducting the necessary amount for each request. If insufficient tokens are available, the request is rejected.
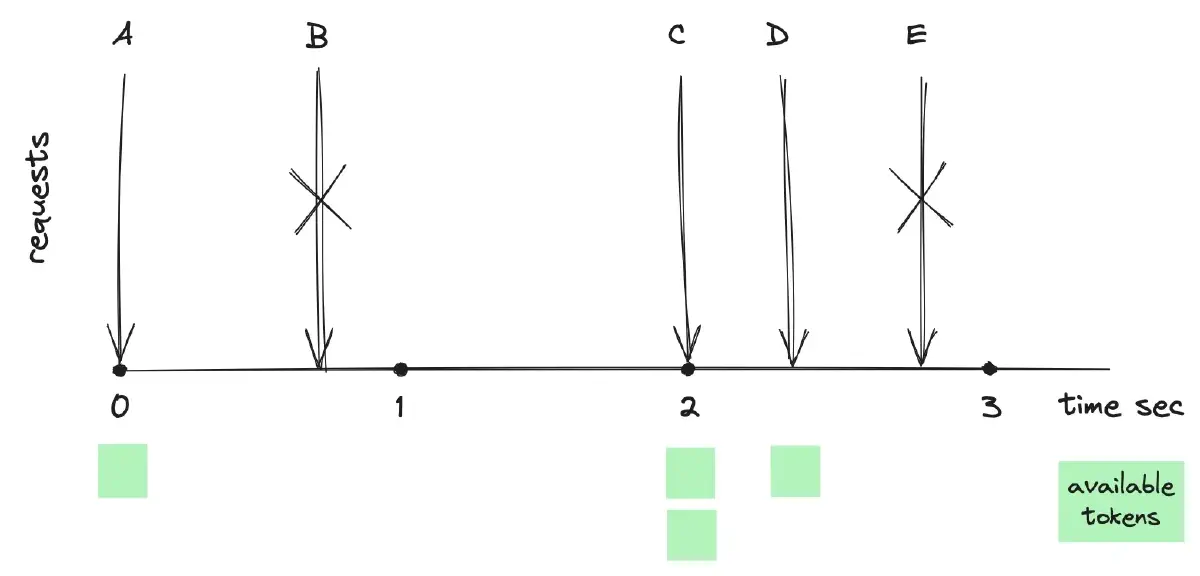
The above diagram illustrates the algorithm with a rate limit set to one request per second and a bucket capacity of two tokens. When request A arrives, the token bucket is initialized with one token, enabling request A to proceed successfully. Request B is rejected due to a lack of tokens in the bucket at that moment. Since no requests are made between the first and second seconds, the bucket accumulates two tokens. Consequently, requests C and D are allowed, with each consuming a token. Request E is rejected as the bucket has been run out of tokens.
Implementing the Token Bucket Rate Limiter
The Token Bucket Rate Limiting algorithm is initialized with the following key properties:
- The maximum number of tokens that the bucket can hold.
- The period over which tokens are replenished within the bucket.
- The number of tokens added to the bucket at each period.
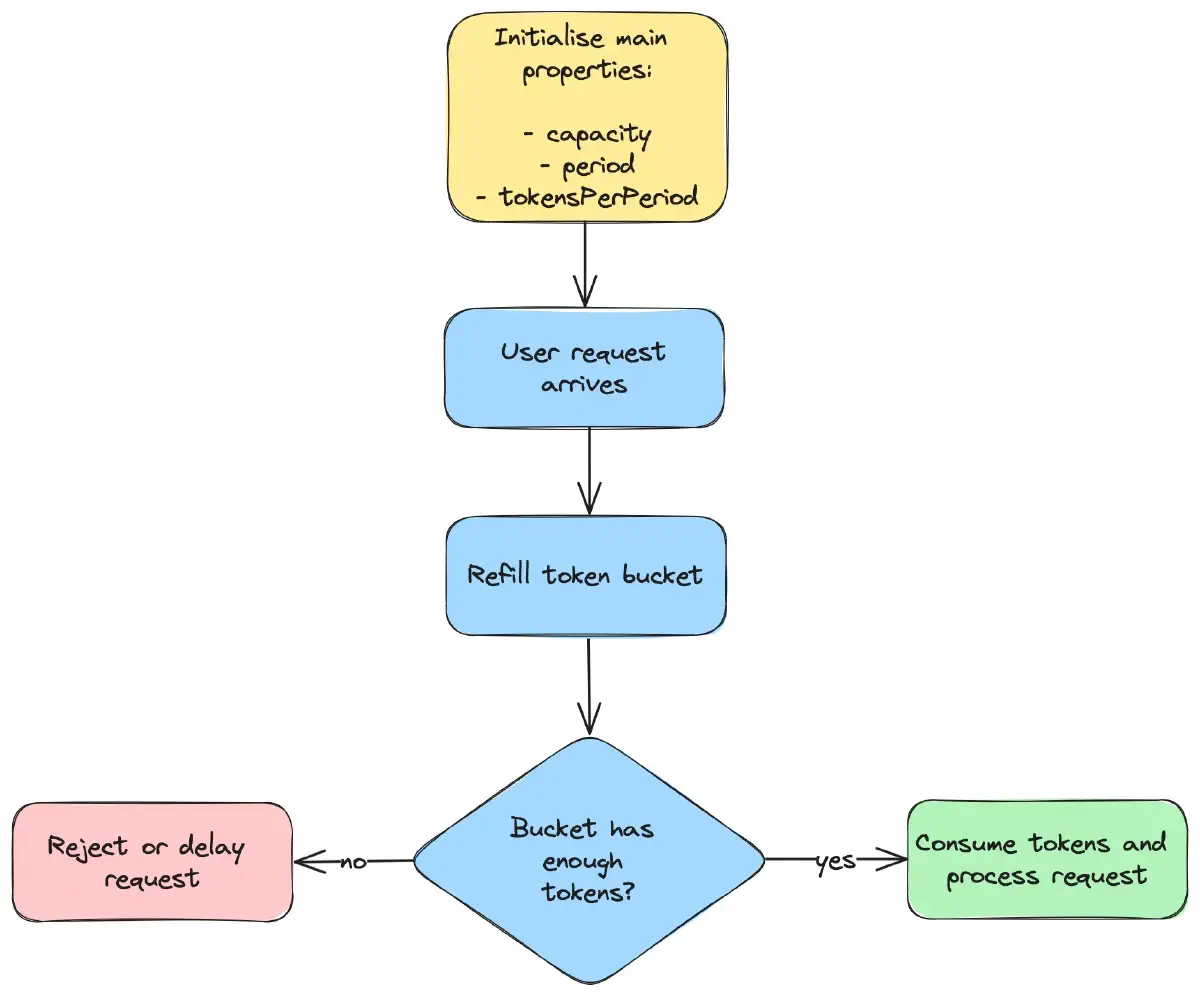
As shown in the flow diagram below, an attempt to refill the token bucket is made whenever a request arrives. The number of new tokens added depends on the time elapsed since the last refill. If the bucket contains a sufficient number of tokens, the necessary amount is deducted, and the request is processed successfully, otherwise, it is either rejected or postponed until enough tokens become available.
To track user-specific buckets, you can use a dictionary that maps each user ID to a pair consisting of the last refill timestamp and the current token count, denoted as Map<String, TokenBucket>. Below is a Java implementation of the Token Bucket Rate Limiting algorithm:
import java.time.Clock;
import java.time.Duration;
import java.util.HashMap;
import java.util.Map;
public class TokenBucketRateLimiter {
private final int capacity;
private final Duration period;
private final int tokensPerPeriod;
private final Clock clock;
private final Map<String, TokenBucket> userTokenBucket = new HashMap<>();
public TokenBucketRateLimiter(int capacity, Duration period,
int tokensPerPeriod, Clock clock) {
this.capacity = capacity;
this.period = period;
this.tokensPerPeriod = tokensPerPeriod;
this.clock = clock;
}
public boolean allowed(String userId) {
// Initialize an empty bucket for new users or retrieve existing one.
TokenBucket bucket = userTokenBucket.computeIfAbsent(userId,
k -> new TokenBucket(clock.millis(), tokensPerPeriod));
// Refill the bucket with available tokens based on
// elapsed time since last refill.
bucket.refill();
// Allow this request if a token was available and consumed,
// Otherwise, reject the request.
return bucket.consume();
}
private class TokenBucket {
private long refillTimestamp; // Timestamp of the last refill.
private long tokenCount; // Current number of tokens in the bucket.
TokenBucket(long refillTimestamp, long tokenCount) {
this.refillTimestamp = refillTimestamp;
this.tokenCount = tokenCount;
}
/**
* Regenerates tokens at fixed intervals. Waits for the entire period
* to elapse before regenerating the full amount of tokens
* designated for that period.
*/
private void refill() {
long now = clock.millis();
long elapsedTime = now - refillTimestamp;
long elapsedPeriods = elapsedTime / period.toMillis();
long availableTokens = elapsedPeriods * tokensPerPeriod;
tokenCount = Math.min(tokenCount + availableTokens, capacity);
refillTimestamp += elapsedPeriods * period.toMillis();
}
boolean consume() {
if (tokenCount > 0) {
--tokenCount;
return true;
} else {
return false;
}
}
}
}The allowed method determines if a user’s request falls within the specified limits. For a new user, an empty bucket is created with initial number of tokens, otherwise, existing bucket is retrieved. The bucket is then refilled with available tokens based on elapsed time since the last refill. The method attempts to consume a token from the bucket to process the current request, allowing the request to pass if a token was available, otherwise, rejecting it.
Simulating Bursty Traffic with Tests
The following Java tests demonstrates the usage of this limiter:
import org.junit.jupiter.api.Test;
import java.time.Clock;
import java.time.Duration;
import static org.junit.jupiter.api.Assertions.assertFalse;
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.mockito.Mockito.mock;
import static org.mockito.Mockito.when;
public class TokenBucketRateLimiterTest {
private static final String BOB = "Bob";
@Test
void allowed_burstyTraffic_acceptsAllAccumulatedRequestsWithinRateLimitThresholds() {
Clock clock = mock(Clock.class);
when(clock.millis()).thenReturn(0L, 0L, 1L, 4001L, 4002L, 4003L, 4004L, 4005L);
TokenBucketRateLimiter limiter
= new TokenBucketRateLimiter(4, Duration.ofSeconds(1), 1, clock);
// 0 seconds passed
assertTrue(limiter.allowed(BOB),
"Bob's request 1 at timestamp=0 must pass," +
" because bucket has 1 token available");
assertFalse(limiter.allowed(BOB),
"Bob's request 2 at timestamp=1 must not be allowed," +
" because bucket has 0 tokens available");
// 4 seconds passed
assertTrue(limiter.allowed(BOB),
"Bob's request 3 at timestamp=4001 must pass," +
" because bucket accumulated 4 tokens" +
" since the last refill at timestamp=0" +
" and now has 4 tokens available");
assertTrue(limiter.allowed(BOB),
"Bob's request 4 at timestamp=4002 must pass," +
" because bucket has 3 tokens available");
assertTrue(limiter.allowed(BOB),
"Bob's request 5 at timestamp=4003 must pass," +
" because bucket has 2 tokens available");
assertTrue(limiter.allowed(BOB),
"Bob's request 6 at timestamp=4004 must pass," +
" because bucket has 1 token available");
assertFalse(limiter.allowed(BOB),
"Bob's request 7 at timestamp=4005 must not be allowed," +
" because bucket has 0 tokens available");
}
}This test simulates a scenario where tokens are accumulated in the bucket and used later on to allow multiple requests to pass. More tests and latest source code can be found in the rate-limiting GitHub repository .
For additional implementations and insights, you can explore open-source resources such as:
- Java rate limiting library based on token-bucket algorithm
- High Performance Rate Limiting MicroService and Library
Refill Strategy: Interval vs. Greedy
The refiller’s goal is to replenish a bucket with tokens based on the elapsed time.
Interval-Based Refiller
The implementation above uses an interval-based refiller to regenerate tokens in the bucket at fixed intervals. It waits for the entire period to elapse before regenerating the full amount of tokens designated for that period. This approach is very similar to how the Fixed Window algorithm works , and it has a similar issue with bursty traffic at the period boundaries.
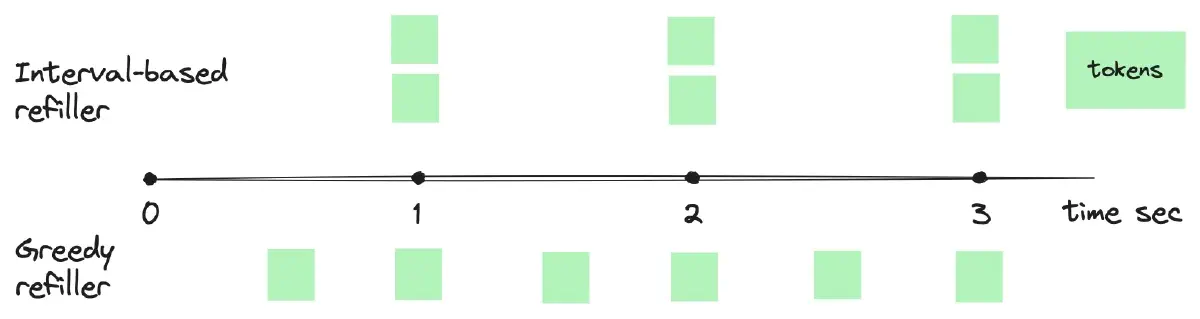
Greedy Refiller: A Smoother Alternative
The greedy refiller, on the other hand, aims to add tokens to the bucket as soon as possible without waiting for the entire period to elapse. As illustrated in the figure above, a greedy refiller with a bucket configuration of “2 tokens per 1 second” would add 1 token every 500 milliseconds, whereas an interval-based refiller would add all 2 tokens at once every second.
Below is a Java implementation for the greedy refill strategy:
void refill() {
long now = clock.millis();
long elapsedTime = now - refillTimestamp;
// Calculate the number of available tokens to add
// based on the elapsed time.
long availableTokens = elapsedTime * tokensPerPeriod / period.toMillis();
// Update the token count and ensure that the total
// does not exceed the bucket's capacity.
tokenCount = Math.min(tokenCount + availableTokens, capacity);
// Adjust the refill timestamp forward by the time
// equivalent to the number of tokens added.
refillTimestamp += availableTokens * period.toMillis() / tokensPerPeriod;
}It provides a smoother token distribution within the time interval and solves the issue of bursty traffic. However, it can be tricky to implement and requires more calculations and updates.
Trade-Offs and Design Considerations
Pros
Bursty Traffic Handling: Unlike the leaky bucket algorithm , the token bucket allows for bursts of requests within the bucket capacity. This means clients can adapt to changing demands and make multiple requests quickly if needed, without being throttled immediately. This flexibility is beneficial for applications with unpredictable traffic patterns.
Efficiency: It is memory efficient, as it only requires a fixed number of tokens to be stored. This can be important in systems with limited memory resources.
Customization: The token bucket allows for easy customization of parameters like token refill rate and bucket capacity. This enables fine-tuning the rate limiting behavior to specific needs and scenarios.
Cons
Complexity: Implementing the token bucket in a distributed environment can be challenging due to potential race conditions. Ensuring consistent token availability across multiple servers requires additional complexity and synchronization mechanisms. Additionally, configuring it properly, especially for applications with highly variable loads, can be difficult. For example, if the token bucket is too small or the refill rate is too slow, it can lead to resource starvation, where legitimate requests are denied because the bucket runs out of tokens too quickly.
Granularity: For use cases requiring extremely fine-grained control over very short periods, the token bucket algorithm may not offer the necessary granularity. This is because it operates on the principle of accumulating tokens at a predefined rate, which might not adjust quickly enough to rapid changes in traffic within those short windows.
Bursty Traffic: The token bucket doesn’t guarantee a perfectly smooth and consistent rate of requests. This can be problematic for applications that require a steady flow of data, as sudden bursts followed by slower periods can disrupt operations.
Common Use Cases
The algorithm’s flexibility in handling bursts makes it well-suited for scenarios where occasional spikes in activity are expected. Below are a few real-world examples of using this algorithm.
Stripe uses the token bucket algorithm to improve availability and reliability of their API:
We use the token bucket algorithm to do rate limiting. This algorithm has a centralized bucket host where you take tokens on each request, and slowly drip more tokens into the bucket. If the bucket is empty, reject the request. In our case, every Stripe user has a bucket, and every time they make a request we remove a token from that bucket.
AWS relies on this algorithm to throttle EC2 API requests for each account on a per-region basis, which improves service performance and ensures fair usage for all Amazon EC2 customers:
Amazon EC2 uses thetoken bucket algorithmto implement API throttling. With this algorithm, your account has abucketthat holds a specific number oftokens. The number of tokens in the bucket represents your throttling limit at any given second.
Summary
The Token Bucket algorithm offers a balanced approach to rate limiting, capable of adapting to dynamic traffic patterns while maintaining simplicity in concept. However, its implementation complexity and the need for careful configuration to prevent resource starvation underline the importance of thoughtful development and deployment in distributed systems.